
В этом модуле вы узнаете, как устроена подготовка любого эксперимента: дизайн — проблема, гипотезы, метрики; правила формулирования гипотез; ошибки первого и второго рода; множественные тесты.
Итак, теперь мы знаем, сколько денег можно ожидать от наших фичей. Мы выбрали самую сильную гипотезу и готовы тестировать ее в A/B — пришло время проектировать эксперимент. Дизайн эксперимента сводится к развернутым ответам на ряд вопросов, которые однозначно определяют наше поведение до, во время и после A/B-теста. Например:
- Какова текущая ситуация и какую бизнес-проблему мы решаем?
- Какую гипотезу проверяем: «Если сделать <то-то> для <такого-то пользователя>, то <метрика Z> повысится на <10(%)>, потому что <то-то>».
- Сколько денег компания заработает, решив эту проблему?
- Какой самый дешевый вариант по разработке теста?
- Какая выборка будет в тесте, и как будем набирать в нее пользователей?
- и т.д.
Пример шаблона для дизайна эксперимента с подробным списком вопросов и пояснениями.
Упражнение. Создайте себе копию шаблона с документацией эксперимента, выберите гипотезу для теста из бэклога своего продукта и ответьте на вопросы страниц 1−3. В большинстве случаев после ответа на все каверзные вопросы у вас пропадет желание проводить A/B-тест, потому что вы увидите в своей гипотезе много уязвимых мест.
Расчет выборки для A/B-теста
Скорее всего, у вас вызовет трудности вопрос из шаблона дизайна эксперимента про минимальный размер выборки. Обратимся к теории, чтобы разобрать его подробнее.
Любой A/B-тест по своей сути является проверкой статистической гипотезы. К счастью для нас, этот класс задач отлично проработали специалисты по математической статистике. Если сильно упростить, то для решения необходимо:
- Сформировать основную (нулевую) и альтернативную гипотезы. В A/B-тестах, как правило, за нулевую гипотезу принимают, что между вариантами A и B нет разницы, а за альтернативную — что разница есть и она вызвана именно нашей гениальной фичей.
- Определить статистический критерий. Это математическое правило, которое помогает нам отвергнуть или принять гипотезу. Выбор правила зависит от того, например, какое распределение имеет величина (метрика, в которую мы целимся в A/B-тесте) и сколько вариантов мы сравниваем. Подробнее выбор критерия обсудим в блоке про анализ результатов.
- Задать уровень значимости (обозначается α). Он определяет вероятность совершить так называемую ошибку первого рода, то есть случайно обнаружить между вариантами A и B разницу, которой на самом деле нет. За стандарт принят уровень значимости 5%.
- Задать мощность критерия (обозначается 1−β). Она определяет вероятность совершить ошибку второго рода, то есть случайно не заметить реально существующую разницу между вариантами A и B. Здесь обычно задают мощность в 80%, то есть вероятность совершить ошибку второго рода — 20%.
- Задать эффект, который мы собираемся обнаружить, то есть прогнозируемый сдвиг метрики. Чем меньше эффект, тем больше надо данных.
Важно понимать, что ошибка первого рода — это ложноположительное решение, а ошибка второго рода — это ложноотрицательное решение. Проще всего запомнить разницу с помощью этого мема:

В интернете множество калькуляторов для расчета выборки и подведения итогов A/B-тестов, но не понимая, как они устроены, можно совершить фатальную ошибку. Например, метрика, на которую вы влияете своим изменением в продукте, может иметь ненормальное распределение или в калькуляторе может быть зашит неподходящий для вашего эксперимента статистический критерий. В обоих случаях велик риск принять некорректное решение. Поэтому мы предлагаем вам самостоятельно рассчитывать размеры выборок с помощью Python.
Чтобы не мучиться с установкой Python на ваше устройство, мы будем использовать Google Colab. Это облачный сервис, который позволяет решать задачи Data Science.
Упражнение: познакомьтесь с калькулятором размера выборки и выполните задания оттуда. Если по какой-то причине вы не можете работать в Google Colab, то для закрепления материала воспользуйтесь калькулятором Эвана Миллера. Но помните — он может подойти не для всех экспериментов.
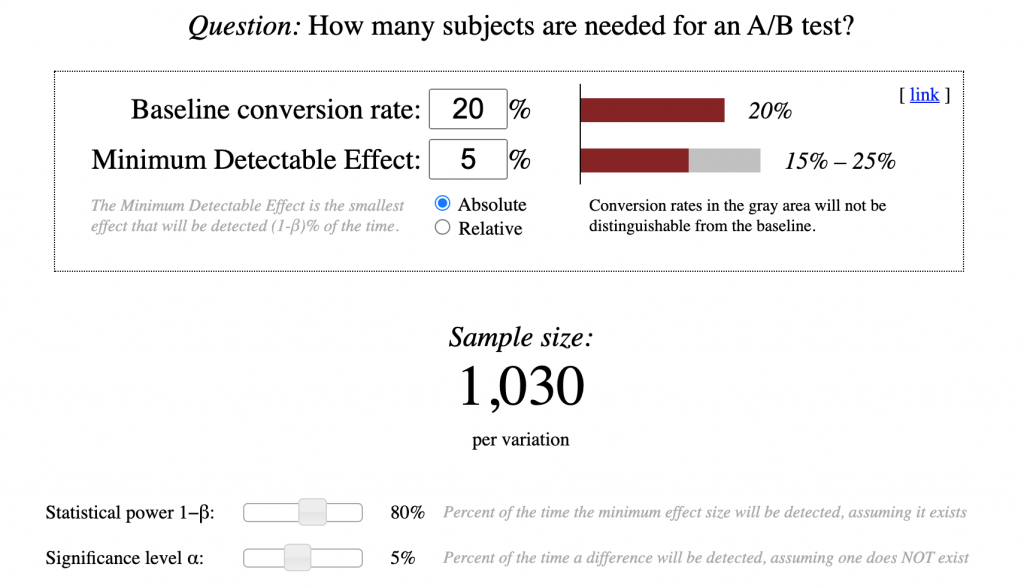
Параметры в нем аналогичные:
- Baseline conversion rate — текущее значение вашей целевой метрики.
- Minimum Detectable Effect — значение, на которое вы планируете сдвинуть вашу целевую метрику в эксперименте.
- Statistical power 1−β — статистическая мощность. Стандартом считается 80%.
- Significance level α — уровень значимости. Стандартом считается 5%.
В этом видео — ответ на практическое задание. Пожалуйста, вначале попробуйте выполнить его самостоятельно.
Множественные или A/B/C-тесты
Часто возникает идея сравнить больше двух вариантов — то есть провести не A/B, а так называемый множественный тест. В некоторых случаях это допустимо и оправданно, но важно держать в уме, что точность такого исследования при том же количестве наблюдений будет ощутимо ниже, потому что растет вероятность совершить ошибку первого рода. А если вы захотите сохранить изначальную точность эксперимента, то придется собирать больше данных. Расчеты таких экспериментов немного сложнее и останавливаться на них в рамках микрокурса мы не будем.
Если вам интересна эта тема — рекомендуем статью на Хабре.