
Коллеги из ExperimentFest рассказывают, чем объясняется качество системы сплитования трафика и как его определить.
В своей работе компании часто сталкиваются с ситуациями, когда системы сплитования трафика для A/B-тестов сломаны. Сломанная система сплитования — это система, которая нечестно распределяет трафик между контрольной и тестовой группой, из-за чего исход эксперимента может объясняться не качеством гипотез, а тем, что система работает с ошибками. Проверкам качества систем сплитования либо уделяется очень мало времени, либо не уделяется совсем.
Мы в ExperimentFest консультируем продуктовые команды и проводим обучающие мероприятия по анализу экспериментов. Недавно к нам обратился заказчик с просьбой оценить их систему проведения A/B-тестов и определить, насколько она честна.
Мы хотим поделиться показательным кейсом о том, почему проверять A/B-тесты стоит через анализ качества A/A-тестов, к чему могут приводить поломки и как их отслеживать.
Мы пишем о менеджменте продуктов и развитии в телеграм-каналах make sense и Продуктовое мышление.
Проблемы, которые возникают из-за неправильной системы сплитования
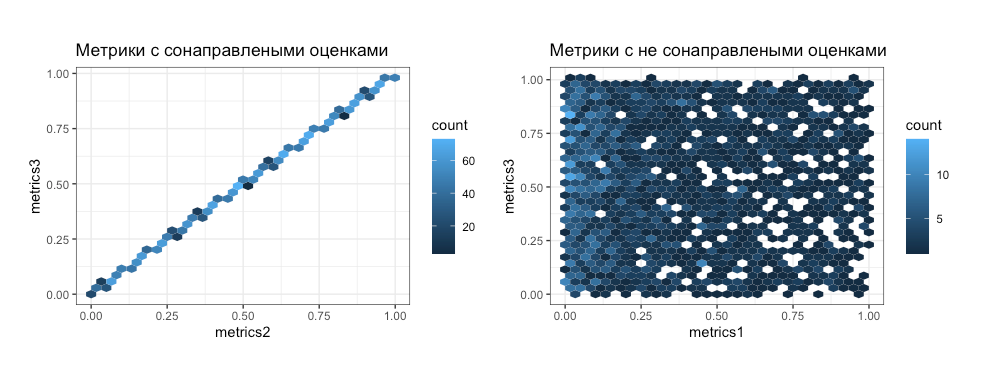
Система показывает некоторой группе пользователей сразу два варианта: A и B
В этом случае эта доля пользователей будет видеть оба варианта эксперимента, что может сильно отразиться на результате. Если такая доля маленькая, ее можно исключить. Если таких пользователей, например, больше 20%, это может стать проблемой.
С зависимыми выборками можно работать статистически: даже в медицинских исследованиях используют последовательные подходы тестирования — когда пациент в начале принимает одну таблетку, а следом другую. Это стоит делать умышленно, потому что в таком случае нужно использовать подвиды статистических критериев (например, t-критерий для зависимых выборок или Bootstrap для зависимых выборок). Если не учесть этого, результат эксперимента будет ошибочным и может приводить к ложным решениям.

Репрезентативность
Система сплитования трафика делит пользователей на равные группы — 50/50. Получаются две сбалансированные выборки. Но если разделить выборку на параметры (город, источник покупки или тип устройства), может оказаться, что пользователи внутри этих параметров поделились неравномерно. Если такое происходит, эффект эксперимента будет объясняться не качеством гипотезы, а проблемой в репрезентативности. И это тоже необходимо фиксировать.
Технические ошибки
Например, не отработал код на клиенте, долгий ответ сервера, не «прорисовалась гипотеза», не все пользователи попали в эксперимент из заявленного сегмента. Важно отметить, что технические сбои могут сильно сказаться на результате эксперимента.
Неправильно посчитанные метрики
Если неправильно посчитать метрику, результат A/A-теста тоже скажется на результате. Такое, например, часто бывает с Ratio-метрикой из-за смещения оценки. Подобный пример рассматривают коллеги из компании Microsoft.
Использование слишком чувствительного статистического критерия
Если вы используется статистические критерии с высокой чувствительностью, например односторонние проверки гипотез, то в этом случае даже в честном A/A-тесте вы можете получать ложный прокрас. Такие методы больше чувствительны к низким эффектам, они чаще приводят к ошибке.
Как проверить систему сплитования
Вернемся к компании заказчика и исследованиям качества их системы сплитования. Мы решили пойти по следующему сценарию:
- Запустить A/A-тест.
- Посчитать метрики качества системы сплитования.
- Оценить репрезентативность распределения трафика.
- Оценить качество системы сплитования. Если в ней есть проблемы, предложить варианты решения.
Шаг 1. Запустили A/A-тест
Мы запустили A/A-тест с текущим алгоритмом сплитования, подождали определенное время (с учетом того, какое окно у той метрики, которую мы хотели проверить на предмет ложных срабатываний) и начали оценку эксперимента.
Шаг 2. Посчитали метрики качества системы сплитования
При проверке системы сплитования мы хотели убедиться, что статистически значимая разница отсутствует. Мы посчитали A/A-тест по следующему алгоритму:
- Симулировали новые A/A. Тест пересчитывался более 10 тысяч раз при помощи симуляции новых A/A.
- Посчитали статическую значимость. В каждом тесте посчитали p-value при помощи статистического оценщика (можно использовать Bootstrap, t-критерий).
- Посчитали метрику качества FPR (False Positive Rate).
- Сделали выводы. На этом этапе проверяется условие α: если условие соблюдается, то система сплитования работает корректно. Затем проверили, что FPR < α: если условие соблюдается, то система сплитования работает корректно.Один из самых важных показателей — FPR (False Positive Rate). Вот по какой формуле считается показатель:
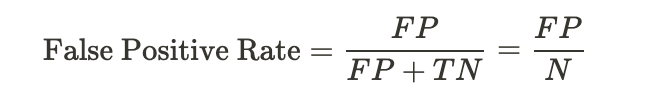
FP — False Positive, TN — True Negative, N — все случаи
FPR позволяет понять, какая доля из всех синтезаций A/A-тестов имеет α равный или меньше 0.05 (если мы хотим отклонить гипотезу на этом уровне значимости).
Если полученный FPR будет составлять 5%, это означает, что в 5% мы ошибаемся, а в 95% правы. В этом случае система сплитования честная. Если FPR будет больше 5%, то система сплитования сломана.
Кроме статистической оценки мы смогли оценить смоделированное распределение полученных pValue.
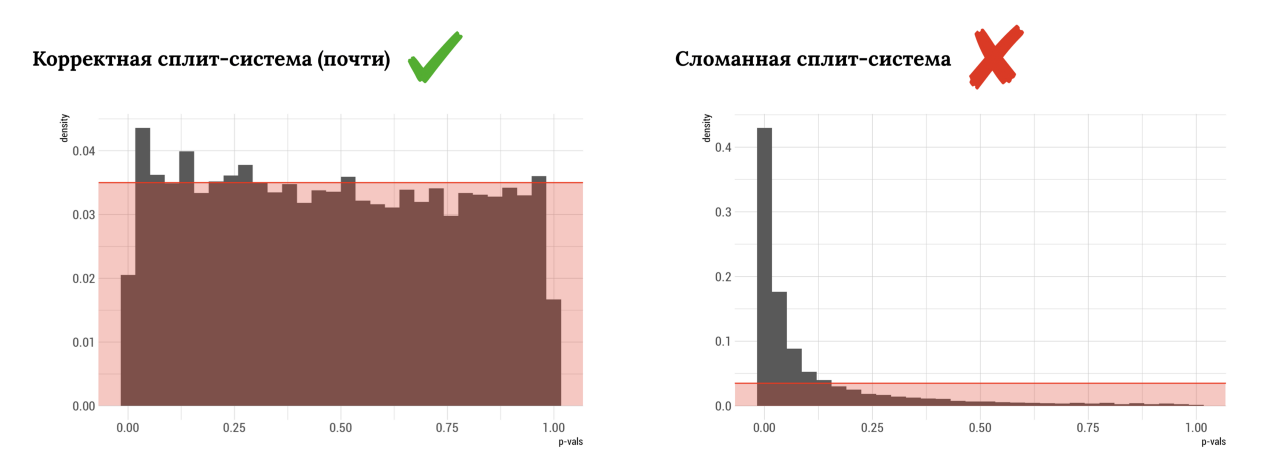
Если распределение pValue после проведенных синтезаций больше похоже на равномерное (как на графике слева), то полученная оценка однородная. В таком случае, вероятнее всего, значимой разницы нет. Если распределение больше похоже на график справа, мы получаем большую долю ложных прокрасов.
У pValue есть теоретическое распределение. При таком подходе мы моделируем форму этого теоретического распределения и оцениваем, в какую сторону оно отклоняется.
Моделирование распределения pValue и FPR — очень доступные и удобные сигналы для проверки систем сплитования. Если у вас в компании есть платформа автоматизации A/B, сигналы удобно вывести для регулярного анализа качества этой системы.
В результате оценки системы сплитования трафика заказчика мы получили FPR, который равен 12,1%. Оказалось, что ошибка достаточно большая: она сильно отклоняется от допустимо-минимальной.
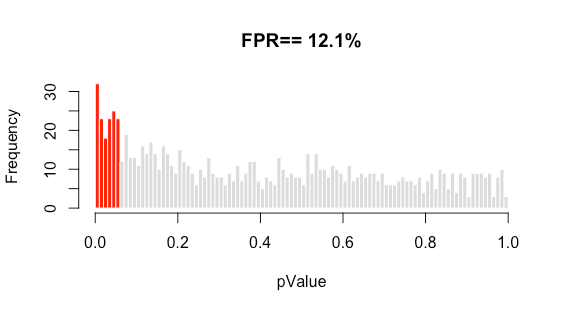
Шаг 3. Оценили репрезентативность деления трафика
Важно, чтобы система сплитования трафика разделяла пользователей внутри параметров равномерно. Именно это мы и решили проверить.
Мы взяли основные параметры, такие как:
- Регион пользователя.
- Браузер и его версию.
- Тип устройства.
- Частоту покупок пользователей.
Оценку репрезентативности можно делать двумя способами: визуальным и статистическим. Визуально можно оценить, насколько сильно отклоняются параметры между группами эксперимента. Проблема тут в том, что у нас нет ориентира, что такое «сильно» и «слабо». Если просто оценивать визуально, мы можем упустить что-то действительно важное.
Для статистической оценки можно использовать специальные критерии, которые помогут определить статистическое различие в долях между параметрами. Для этого можно использовать критерий Хи-квадрат или Кохрана-Мантеля-Хензеля для больших таблиц. Вот какие результаты мы получили:
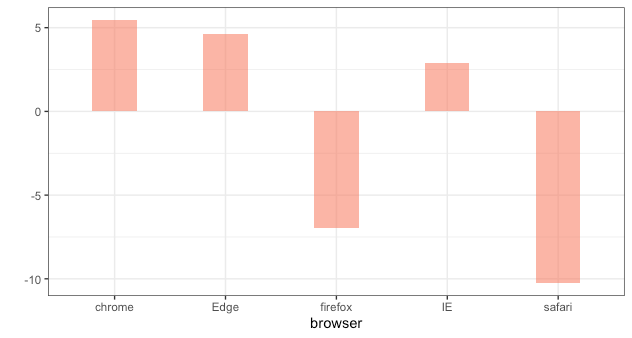
Оказалось, что репрезентативность нарушается в параметре «Браузер». Это сильно сказалось на FPR, из-за чего A/A-тест показывал значимое изменение.
Пользователи, которые заходили на сайт через закладки в браузере, не распознавались сплитовочным скриптом из-за устаревших URL’ов. Сайт пережил реконструкцию иерархии URL’ов. После попытки входа на URL пользователи перенаправлялись на актуальную страницу, но вариант теста для пользователя не определялся. Это было обусловлено работой сплитовочного скрипта, который в процессе исправили. Следующие A/A-тесты показывали допустимый FPR.
A/A-тесты и качество системы сплитования — очень важно. Если за этим не следить, эксперименты могут показывать результат, который объясняется не качеством работы, а случайным эффектом, который зависит от технической неполадки. Поэтому регулярно проверяйте свою систему A/B-тестирования на качество, чтобы результат эксперимента приводил исключительно к правильным решениям. Чтобы проверить свою систему сплитования, следуйте этому алгоритму:
- Запуск A/A-теста.
- Подсчет метрик качества системы сплитования.
- Оценка репрезентативности распределения трафика.
- Оценка качества системы сплитования.
- Улучшение системы A/B-тестирования.
Если вы хотите лучше понимать, как работают A/B-тесты, запишитесь на онлайн-интенсив ExperimentFest. На интенсиве вы сможете разобрать основные теоретические допущения анализа данных с точки зрения математической статистики, закрепив их на реальных кейсах.









