
Сам факт проведенного интервью не сделает ваш продукт лучше — это только начало работы и один из этапов принятия продуктовых решений, запуска новых продуктов или фич.
Когда интервью закончилось, начинается аналитическая работа: необходимо тщательно обработать данные, наглядно и удобно их скомпоновать, правильно интерпретировать, сделать выводы, отсеять лишние гипотезы или сгенерировать новые, провести количественные исследования и принять решения о продукте. Только так можно получить качественный набор инсайтов.
Елена Гергерт, менеджер по развитию продукта в Контуре, рассказала, как правильно анализировать результаты глубинок, каких ошибок избегать и поделилась шаблоном для обработки данных интервью.
Хорошие причины провести интервью
В отличие от профессиональных исследователей, менеджеры продуктов нередко полагают, что интервью всегда уместно, и применяют его для решения любой исследовательской задачи. Однако для начала стоит спросить себя: «А для чего мне интервью?» И если ответ «понять частотность сценария», «понять, существует ли вообще такой сценарий», то, скорее всего, интервью не подойдет. Лучше взять количественные данные, посмотреть выгрузки пользовательских сессий.
Да и вообще, прежде чем идти на интервью, очень полезно поговорить с экспертами, посмотреть на конкурентов, провести кабинетные исследования. То есть когда цель интервью не просто почувствовать эмпатию к пользователю, а проверить гипотезу, уточнить какие-то сценарии, причины поведения или понять целевые результаты работы, надо подготовиться, собрать все возможные материалы и не бежать сразу к пользователям.
Мы пишем о менеджменте продуктов и развитии в телеграм-каналах make sense и Продуктовое мышление, а тажке делаем make sense podcast.
Хорошие причины провести интервью:
- Проверить или валидировать гипотезу, найти проблему. Например, мы предполагаем, что у пользователя есть проблема — кривой или незакрытый сценарий. И тогда с помощью интервью мы пытаемся проверить, действительно ли пользователи сталкиваются с такими проблемами.
- Узнать и определить основные сценарии в продукте, понять, через какие этапы проходит пользователь и с чем сталкивается на этом пути.
- Понять причины тех или иных решений пользователей, их внутреннее состояние. Например, человек говорит: «Мне важно закрыть документ в течение дня», — тогда с помощью интервью мы можем выяснить, почему ему важно закрыть документ в такие сроки. Или можно узнать целевой результат действия, то есть почему нужно прийти к такому результату, почему именно такую картинку пользователь считает целевой или конечным шагом в работе.
- Развивать эмпатию к своему пользователю. Когда продакт никогда не видел свою аудиторию, никогда с ней не соприкасался и не взаимодействовал, это тоже может быть способом почувствовать, понять, кто твой пользователь, на каком языке он говорит. Именно на уровне эмпатии.

Шаг 1. Фиксируем информацию
Идеальный вариант фиксации интервью — записать всю встречу, сделать аудиозапись. Тут важно предупредить респондента, что вы будете писать интервью. Мы никаких бумаг не подписываем, но на словах проговариваем: «Могу ли я сделать аудиозапись встречи, чтобы потом корректно обработать данные и ничего не упустить? Информацию мы не выносим вовне, эта запись — только для меня».
Чаще всего респонденты соглашаются — особенно если это удаленное общение. Хотя в моей практике был случай, когда человек сказал: «Нет, я против». И к этому тоже нужно быть готовым, поэтому под рукой всегда должны быть запасные варианты вроде листочка с ручкой или заранее открытый электронный документ.

Если вы приходите на интервью вместе с коллегами, можно попросить их фиксировать основные моменты — по сути, тогда сразу получается готовый транскрипт.
Надо ли повторно контактировать с респондентом после интервью?
Чаще всего нет. Обычно мы проводим интервью и на этом ставится точка: прощаемся с респондентом и благодарим его. Однако для этого в процессе интервью важно следить за двумя моментами:
- Отслеживать скрипт, чтобы задать все нужные вопросы и ничего не упустить.
- Чувствовать тему, понимать, куда еще стоит копнуть и какие дополнительные вопросы задать.
У нас в Контуре не бывает такого, что мы провели интервью, а потом перезваниваем и говорим: «Я еще хочу спросить об этом и этом». А вот если мы проводим интервью на очень болезненную тему, у пользователей есть реальные проблемы и они видят, что мы готовим какое-то решение, они сами могут сказать: «А можно я посмотрю на то, что вы придумаете, потестирую ваше решение?» Однако это уже будет не повторное интервью, а совсем другой этап — мы придем к таким пользователям тестировать прототип или с чем-то еще.
Еще один сценарий, когда мы повторно контактируем с респондентами, — если в ходе интервью нас забрасывают сложными вопросами, на которые мы не можем ответить сразу. В этом случае мы берем паузу в несколько дней, а потом перезваниваем и даем ответы или передаем запрос в техподдержку. Но это уже плоскость, скорее этики и теплых отношений с пользователями продукта, а не часть исследования.
Читайте также: Гайд: как подготовиться к глубинным интервью и провести их максимально эффективно
После интервью мы можем собирать дополнительную информацию о респонденте, чтобы понять, насколько его ответы объективны. Допустим, он говорит: «Да я вообще уже замучился, ничего не понимаю, все неудобно. У вас ничего толком не работает». Мы смотрим отчеты и видим, что ни один электронный документ не был отправлен данным пользователем, а значит респондент не мог оценить удобство и понятность сервиса, потому что не работал в нём. Отсюда вывод: скорее всего, нам рассказали о проблемах, которых нет.
Бывает и противоположный вариант. Пользователь говорит: «Да я вообще в эту часть системы не хожу и проблем у меня нет». А мы открываем данные техподдержки и видим, что за последний месяц он прислал пятнадцать обращений и вопросов. У такого поведения может быть несколько причин: пользователь просто не видит в этом проблемы, исследователь не смог установить с ним нормальный контакт, пользователь не хочет выносить наружу какие-то чувствительные данные.
Шаг 2. Расшифровываем запись
Если тема и проблематика новые для исследователя, лучше расшифровывать запись почти дословно: в дальнейшей работе пригодятся особые слова и термины респондента, знание стилистики его речи, доскональное понимание процессов и логики работы.
Если тема знакомая или есть ограничения по времени, можно в расшифровке отмечать ключевые идеи или фиксировать тезисно слова респондента.
Во всех случаях полезно использовать тайминг – временные отметки. Я ставлю время в расшифровке, когда меняется тема или встречается важный инсайт. Так проще возвращаться и переслушивать нужные места или делать нарезку.
Как можно расшифровывать записи интервью:
- Своими силами или силами коллег — просто включать запись и делать расшифровку.
- Через фрилансеров — можно размещать заказы на расшифровку на фриланс-биржах или найти каких-то постоянных фрилансеров. Хорошо расшифровывают записи судебные стенографисты. В этом варианте важно задать удобные для вас стандарты оформления.
- С помощью сервиса zapisano.org — в нем удобный интерфейс, при загрузке записи сервис показывает четкие сроки работ, а документы на выходе оформлены по стандартам и расшифрованы достаточно грамотно.
- Через субтитры на YouTube — аудио конвертируется в видео со статической картинкой. Это видео вы заливаете на свой YouTube-канал и получаете автоматически сгенерированные субтитры.
- Через Яндекс Speech.
В Контуре есть своя программа, которая помогает распознавать речь. Мы пропускаем запись через нее, а потом дорабатываем расшифровку. Однако идеальных автоматических инструментов для транскрибации записей на русском языке пока не существует.
Отдавать запись на расшифровку в сторонние сервисы, фрилансерам или в другие отделы можно, только если информация в интервью не очень чувствительная. Например, в Контуре существует отдельный департамент, в который можно отдавать данные на расшифровку.
Шаг 3. Обрабатываем данные: смотрим на факты
После расшифровки мы обычно закидываем весь текст в табличку и разбиваем по строкам — ключевым темам или каким-то критериям. В столбиках — разные респонденты.
Например, в строках могут быть как характеристики респондентов — возраст, должность, тип, размер бизнеса — так и основные вопросы: как вы обычно ищете документы, каким ПО для поиска пользуетесь, что вас беспокоит, что вам интересно, что понравилось. По строкам с ключевыми темами мы раскидываем весь текст — это первый этап сортировки.
Если тема знакомая, мы ее уже исследовали и достаточно хорошо знаем сценарии использования, проблемы клиентов, а в интервью просто уточняем детали, можно не делать полную расшифровку беседы, а слушать запись и сразу раскидывать ключевые мысли по строкам таблички.
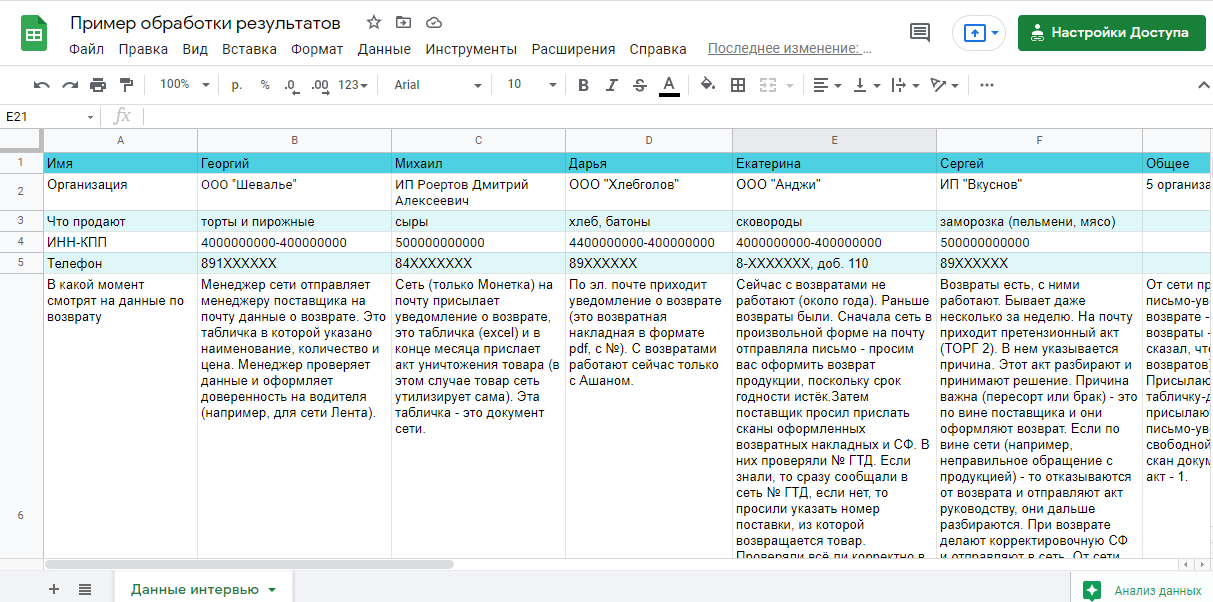
Как устроена таблица.
- Блок с общей информацией о респонденте. Как его зовут, должность, из какой он компании, что компания продает, телефон. Еще мы иногда ставим ИНН и КПП.
- Ответы на главные вопросы. Например, если мы исследуем тему возвратов, то вопросы могут быть следующие: в какой момент в компании смотрят данные по возврату, печатают ли документы и для чего, на какие поля смотрят, важна ли причина возврата и т.д.. Здесь в каждой ячейке — фрагмент интервью с конкретным пользовательским сценарием. В строках текст может быть лаконичным: «да» или «нет» (например, вопрос обращает ли респондент внимание на штрих-код товара) или содержать большие фрагменты интервью (например, вопрос про печать документов).
- Дополнительный блок, пометки. Этот блок идет вне скрипта, вне списка вопросов интервью. Сюда мы заносим то, что не связано с целями конкретного интервью: что еще болит у пользователей, какие у них пожелания, о чем еще они переживают. Например, все респонденты говорят: «Мы работаем с возвратами». А двое мимоходом отметили, что скоро выйдет новый закон, который отменит возвраты. Такая информация со временем может стать ключевой.
- Обобщение, краткие выводы. Обычно в конце таблички я делаю верхнеуровневые выводы, обобщаю результаты всех интервью: например, отмечаю, что пяти пользователям из десяти приходит письмо-уведомление о возврате. Тут важно следовать фактам, не выдумывать, не давать свои интерпретации: если есть что-то общее — выделить это общее, если сценарии отличаются, отметить это.

Таким образом, мы получаем не просто набор кейсов, а структурированный материал для поиска инсайтов, оценки гипотез и понимания сценариев работы.
Табличка — не единственно возможный способ обработки данных. Табличный формат хорошо подходит для проблемных интервью и JTBD. Например, CJM удобнее сразу раскидывать по доске Miro — размещать ключевые инсайты на карте пользовательского пути.
Шаг 4. Интерпретируем первичные данные
На этом этапе важно не говорить о «типичном» — пока это всего лишь данные в рамках интервью. Потому что интервью — качественное, а не количественное исследование, и мы не можем сказать достоверно, типичен ли тот или иной сценарий для наших пользователей. Да, он может быть типичным, а может быть результатом случайного совпадения — просто среди нескольких респондентов оказалось несколько человек с похожими сценариями.
Допустим, смотрят наименование 5 из 10 респондентов, смотрят количество — 10 из 10 респондентов, а номер партии — только один респондент. Однако на генеральной совокупности эти 5 из 10 могут превратиться в 10%, а 1 из 10 — в 20%. Таким образом мы систематизируем все ответы количественно (напомню, это просто предварительная обработка результатов интервью, которую необходимо будет проверять статистически).
Как оценить степень случайности или типичности полученных результатов — расскажу чуть ниже. Спойлер: важно учитывать выборку — каких респондентов приглашали на интервью.
После такой первичной обработки данных у нас получается фактология по конкретным пользовательским сценариям и кейсам. И из нее уже можно начать формирование отчета. В нем могут быть основные факты: столько респондентов работает через веб, столько — через отдельный модуль, столько ходит в Диадок.
И здесь предварительно начинается разделение: есть что-то типичное для наших респондентов и что-то нетипичное. Например, кто-то ходит в Диадок, кто-то запускает специальный модуль, а кто-то пользуется еще каким-то решением. На основе этих фактов мы генерируем гипотезы или сопоставляем их с теми гипотезами, которые хотели проверить с помощью интервью.

И хотя это только первый шаг, на нем уже можно поставить точку — фактура готова. Табличку с результатами или отчет в текстовом виде исследователь может передать менеджеру продуктов. А если исследователь уже достаточно опытен, он может и самостоятельно интерпретировать результаты в рамках гипотезы, которую проверяли с помощью интервью.
Например, мы выяснили (инсайт): пользователи не понимают что делать, когда контрагент не подписал электронные документы. Допустим, только двое из восьми респондентов знают что можно выставить корректировку или исправление. Остальные не знают этого и либо действуют наугад, либо звонят в техподдержку. После этого аналитики, менеджеры продуктов, проектировщики могут подхватить эти выводы и самостоятельно закончить исследование.
А можно пойти дальше: понять насколько массовая проблема (запросить количественные данные у техподдержки, выгрузки по действиям пользователей с не подписанными документами и т.д.), выяснить причины такого поведения и ожидания пользователей. Все это может повлиять на выбор варианта решения проблемы: изменить интерфейс — например, добавить подсказку; поменять логику работы продукта; автоматизировать процесс и т.п.
Итак, на этом этапе мы получаем фактуру — реальные примеры, истории, кейсы проблемы, ожидания отдельных людей или представителей компании.
Как понять насколько типичные сценарии и проблемы мы получили в интервью? Ведь нельзя автоматически перенести все выводы качественных исследований на генеральную совокупность пользователей — статистически они еще не проверены. Поэтому важно разобраться: результаты интервью характерны для всех пользователей, для отдельной группы или вообще только для нескольких человек? А чтобы правильно ответить на эти вопросы, необходимо учитывать контекст — мы уже знаем своих пользователей или пока нет.
Если мы уже знаем своих пользователей
В этом случае мы готовимся заранее, внимательно изучаем свою выборку — потенциальных или реальных пользователей. Допустим, пытаемся понять, отправка документов для новых и старых пользователей — это одно и то же действие или нет.
И если мы видим, что паттерны и сценарии поведения отличаются, а интервью мы при этом провели только со старыми пользователями, надо четко понимать: все наши выводы будут верными только для тех, кто уже знаком с электронным документооборотом и нашим продуктом. Однако если мы видим, что сценарии не отличаются, выводы можно распространить на всю совокупность.
Эту работу важно проделывать еще до интервью — смотреть, кто из респондентов нам подходит и почему. То есть на интервью мы приглашаем не случайных представителей той или иной компании, не тех, кто первым согласился поучаствовать в исследовании, и не наших знакомых или друзей. Мы заранее определяем критерии, которые могут повлиять на результат, и уже исходя из этого подбираем респондентов. Например, если мы предполагаем, что проблема возникает только у бухгалтера по сверке, нет никакого смысла общаться с бухгалтерами по зарплате.
Если мы почти не знаем своих пользователей
Такая ситуация может возникать в новых продуктах, при выходе на новые рынки или когда в ходе интервью мы накопали что-то уникальное и неожиданное. Тогда придется работать непосредственно с данными и разбираться.
Например, мы провели интервью и внезапно выяснилось, что у пользователей, которые совсем недавно перешли с бумажных документов на электронные, возникают вопросы: насколько электронный документооборот безопасен, как долго хранятся электронные документы, как работать с налоговой? В этом случае необходимо уже задним числом идти и смотреть, сколько у нас новых и старых пользователей. И уже после этого экстраполировать первичные выводы на разные группы пользователей.
Ошибки в анализе интервью
Пользователь — не эксперт. На интервью задавайте респонденту вопросы о том, как он на самом деле работает в системе, с чем он сталкивался на практике, какие проблемы у него есть. Не стоит пытаться валидировать на нем свое решение и ставить его в роль эксперта — то есть копать не его реальный опыт, а его мнение о том, как все должно быть устроено.
На интервью мы проверяем, а не подтверждаем. Например, если задать вопрос: «Вам будет удобно здесь создавать и отправлять документы?» — то человеку проще сказать: «Да, конечно». Однако такой ответ легко может оказаться недостоверным, его нельзя использовать, делая выводы.
Интервью — это качественный метод. Нельзя автоматически переносить выводы, результаты интервью, пользовательские сценарии и истории на всех. Например, мы провели 10 интервью и один пользователь очень эмоционально рассказал, как он страдал, когда подключался к нашей системе. Такая эмоциональная картина может оставить в нас отпечаток и засесть в голову. Поэтому при анализе данных важно смотреть: страдал только один, а девять говорили, что спокойно все прошли, вспоминали каждый свой шаг и при этом не говорили о какой-то боли, или, действительно, все девять или десять респондентов отмечали, что у них возникали сложности на том или ином этапе. То есть какие-то яркие эмоциональные истории могут заслонить реальные факты.
И даже если какой-то кейс встретился у нескольких пользователей, надо поискать подтверждение частотности такого сценария: посмотреть запросы в техподдержке, спросить у менеджеров по продажам — в общем, попытаться от истории перейти к цифрам.
Лояльные пользователи— это не все пользователи. Особенно такая проблема характерна для небольших новых продуктов, которые нередко проводят интервью и получают инсайты только от постоянных пользователей. В итоге у них вырисовывается радужная картина: продукт отличный, пользователям все нравится. Однако если респонденты всегда одни и те же, то и продукт мы сделаем только для них. А надо понимать, что выборка, на которой мы проводим интервью, должна быть не случайной, а осознанной, осмысленной, выстроенной по определенным правилам.
Шаг 5. Используем результаты в работе над продуктом
Из интервью может появиться гипотеза, и эта гипотеза пойдет в проверку. И тут есть нюансы: если вы — стартап, для вас может оказаться дешевле и быстрее запилить продукт или фичу и посмотреть, работает это или нет, покупают или нет ваше решение. А если у вас большой продукт, в котором много пользователей и они работают с ним достаточно давно, то, скорее всего, придется проверять гипотезу по-другому.
Тут есть два варианта:
- Обратиться к эксперту. Когда продукт большой и серьезный, у него уже сложился пул клиентов, в отрасли наверняка будут эксперты. Можно пойти к ним и поговорить: «Вот, смотри, что мы накопали. Что скажешь?» И эксперт ответит: «Настоящая бомба! Надо копать в эту сторону», — или: «Нет, туда можете даже не смотреть».
- Посмотреть на конкурентов и понять, есть ли у них решение в рамках вашей гипотезы. Бывает, что у конкурентов уже есть решение и вы опоздали — а значит, вам нужно срочно наверстывать время, потому что это уже какая-то стандартная база, без которой пользователи вас не выберут. А бывает, что у конкурентов ничего подобного нет, и тогда надо попытаться понять — они просто не догадались так сделать или попробовали и не взлетело, проблема оказалась надуманной.
- Провести новое исследование: количественное (опросы, выгрузки, анализ данных из системы) или юзабилити-тестирование (проверка решения).
В итоге результаты интервью используются как для поиска новых идей развития продукта, так и для уточнения текущих сценариев работы пользователей.
Как долго хранятся результаты интервью и когда к ним обращаются
Мы храним результаты исследований максимально долго и стараемся ничего не удалять. У нас есть специальное хранилище, куда мы складываем все исследования.
Структура примерно такая: проект, тематика, исследование с указанием дат.
- KONTUR UX – EDI – массовые действия – подтверждение заказа (03.20)
- KONTUR UX – EDI – массовые действия – архивирование заказа (03.21)
Читайте также: Где хранить результаты исследований и по каким принципам организовать базу инсайтов?
Для чего нам это нужно:
- Пока идет работа над гипотезой, продуктом или фичей, регулярно возникает необходимость вернуться к изначальному артефакту и уточнить какие-то детали. Например, мы делаем поиск и вдруг засомневались, нужны ли сразу все фильтры или для MVP достаточно двух ключевых, а остальные можно добавить в следующем релизе. А если из таблички мы не понимаем, для чего пользователю тот или иной фильтр, то можем даже переслушать аудиозапись или внимательно изучить транскрипт и посмотреть, что еще было связано с поиском, почему именно этот фильтр пользователь считает самым важным и не готов без него работать.
- Когда проводится интервью, пользователь или клиент рассказывает много всего интересного и полезного. Особенно если удается задеть проблемную тему или навести его на какой-то инсайт. Например, мы копали одну тему, а зацепились за другую. Тогда данные исследования будут полезны для формулирования новой гипотезы, и мы можем обратиться к ним снова, чтобы найти дополнительную информацию и запустить новое исследование.
- Мы храним артефакты по интервью для истории, потому что бывает так: есть продукт, в нем уже что-то реализовано и этим пользуются клиенты, а потом вдруг меняется закон, меняются тренды и подходы к работе. А так как прошло много времени, то мы уже забываем, почему у нас в продукте что-то реализовано именно так, а не иначе: например, почему мы сделали два фильтра, а не пять. В этом случае удобно вернуться к результатам исследований и прояснить логику текущего решения.
- Мы смотрим на своих пользователей в динамике. Например, сейчас электронными документами никого не удивишь, а девять лет назад, в 2012 году, когда рынок электронного документооборота еще только раскачивался, мы много общались с бухгалтерами на эту тему. И они говорили: да, это здорово, интересно, что так быстро все будет передаваться — но это какое-то будущее, на нашем веку такое не заработает. И подобные коренные изменения жизни, сценариев, восприятия технологий — интересный источник вдохновения, который может подтолкнуть на то, что прямо сейчас кажется невозможным, года через три станет нормой, а лет через пять — вообще фичей по умолчанию в любом продукте.
- У нас много продуктов, поэтому какие-то идеи и гипотезы рождаются на их стыке. И чтобы не копать одну и ту же тему и не опрашивать одних и тех же людей по несколько раз, мы можем обращаться к результатам исследований из других продуктов. Например, мы решили привлечь новую аудиторию — автомастерские, но еще никогда не работали с ними. Тогда мы смотрим, были ли исследования автомастерских у других продуктов, и можем взять оттуда определенные сценарии, инсайты.
Выводы
- Интервью — хороший способ понять мотивы пользователей и развить эмпатию к ним.
- Не стоит проводить интервью «в любой непонятной ситуации» — это не универсальный исследовательский метод и у него есть свои границы применимости.
- Респондентов для интервью необходимо подбирать осознанно — так, чтобы они представляли все группы пользователей, которые вы хотите изучить.
- Необходимо избегать типичных ошибок в анализе интервью и помнить, что пользователи — не эксперты, данные интервью — это не статистические выводы, лояльные пользователи — это лишь один из пользовательских сегментов, на интервью мы не спрашиваем о будущем, а расспрашиваем респондента о его личном опыте.
- Цепочка обработки результатов интервью и принятия решений на их основе состоит из четырех шагов: фиксируем информацию (записываем интервью), расшифровываем запись, обрабатываем данные, интерпретируем первичные данные, принимаем продуктовые решения или запускаем количественные исследования на данных из интервью.
- Стартапы могут сразу брать гипотезы из интервью в работу, чтобы быстро и дешево проверять их. Крупным продуктам лучше сначала проверить гипотезы количественными методами.
Дополнительные материалы
- Блог Контура на Medium об исследованиях
- КонтурГайды для проектировщиков и исследователей
- Подкаст make sense о поиске респондентов для исследований — способы, каналы, инструменты и ошибки рекрутинга
- FISH: простой фреймворк анализа интервью для продакт-менеджера
- Гайд: как подготовиться к глубинным интервью и провести их максимально эффективно
- Как научить разработчиков и продуктовую команду понимать пользователей и проводить интервью
- Как искать контакты топ-менеджеров из энтерпрайза для CustDev и выходить на них
- ЛПР для исследований в малом и микробизнесе: кто они, где их искать и как на них выйти
- Где хранить результаты исследований и по каким принципам организовать базу инсайтов?
- Interviewing Users: How to Uncover Compelling Insights
- Как проверять гипотезы с помощью проблемных интервью: пошаговая инструкция
- Восемь типов ошибок в глубинных интервью
- Интервью. Как провести глубинное исследование и выявить потребности пользователей
- «Распаковка» интервью и юзабилити-тестов: как ускориться, не потеряв в качестве
- Фиксируем результаты UX-тестирования интерфейса на бегу: экономим время и обходимся без объемных документов









